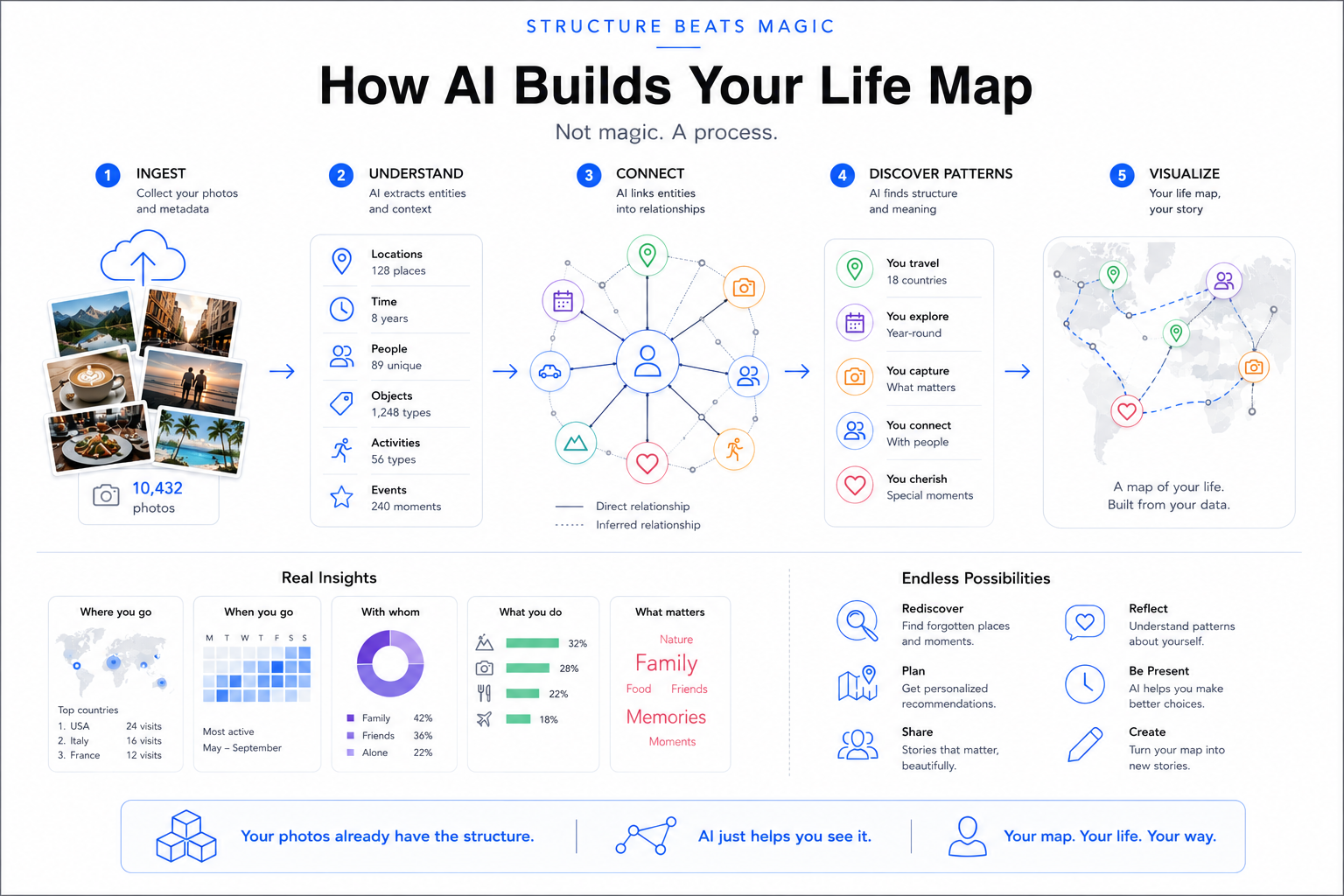
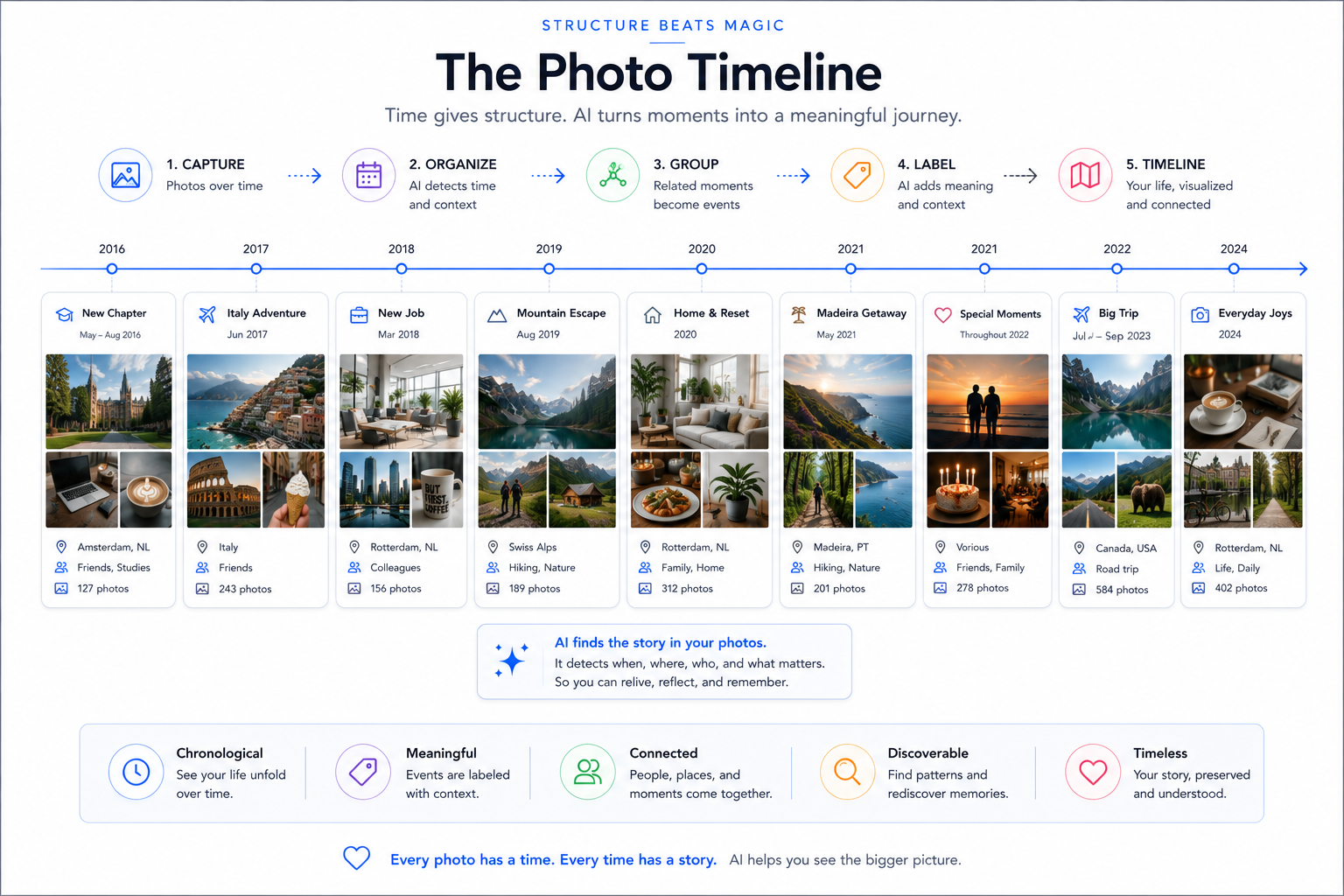
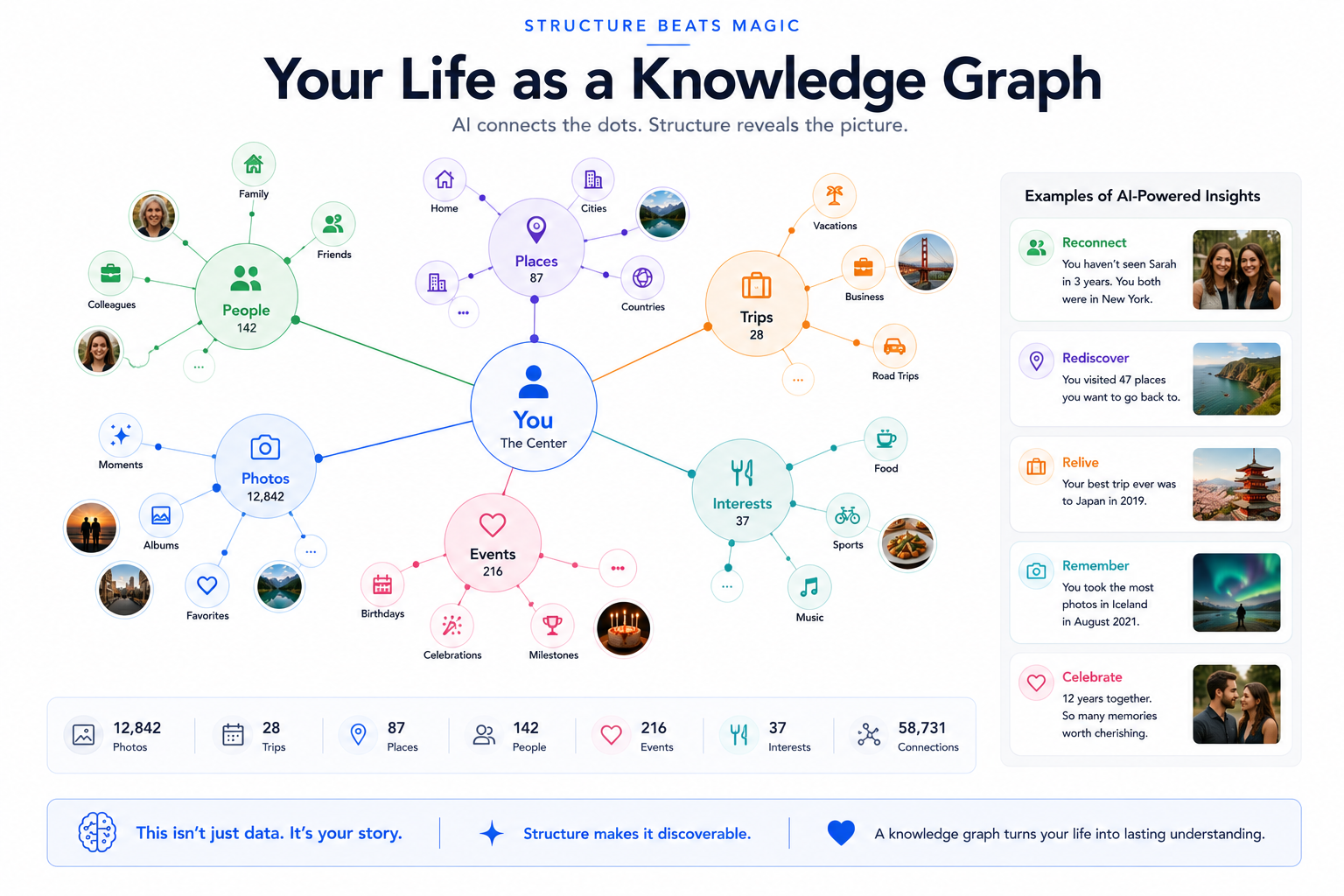
The components that make it work
Everything below is a piece I actually run. It starts with the spine that ties them all together — the daily note.
The daily note — your life, written by your data
One note per day, largely auto-filled from your own data — where you were, what you spent, what you captured, how you slept. Then it rolls up, automatically, from day to week to month to year. A living record you barely have to write.
A spending record is a life record — where you went, what you did, who you saw. One of the richest, most honest signals you own.
Receipts and documents (e.g. via a scan app) quietly reconstruct what actually happened on a day — captured, not remembered.
Your movements over years. With rules, raw coordinates become meaning: at work, at the gym, on a trip — context, automatically.
Steps, sleep, workouts from your phone (Health Connect) — the body's side of the story, folded into the same daily record.
Trip management reimagined — the useful idea behind apps like TripIt, rebuilt on your own data so you own it instead of renting it.
Photos, mail, calendar, highlights — every source a thread; the daily note is where they're woven together.
Not just what you prefer — where you intend to go
Document your intentions with AI, and the system can reflect them back against what your data shows actually happened — direction versus reality, gently. Not a scorecard, not pass/fail — a mirror that helps you steer. Your modeled self holds taste and intent.