
The shelf I couldn't ask anything
I own a lot of books on how to model data. Inmon on the data lakehouse. Linstedt and Olschimke on Data Vault 2.0. David C. Hay's Data Model Patterns. Kimball. Snowflake, dbt, observability, data quality. Years of buying the canon, one title at a time, because each one had a piece of the argument I was trying to assemble for myself.
And I had read almost none of them across each other.
That's the quiet failure of a personal library. Each book is a sealed room. You can be in one at a time. You cannot stand in the hallway and ask all of them the same question at once — "where do these authors disagree about what a 'business key' is?" — because the books don't talk, and neither does the reader they live in. They're an archive. Stuff I kept. Not a source I could query.
The thing that finally forced the issue was mundane: my e-reader app announced it was shutting down. The familiar way of getting a book I'd bought onto my own disk was disappearing, with a date attached. I had a narrow window to either hold my own copies of the books I'd paid for — or quietly lose the ability to.
So I sat down to solve "back up the books I own," and I came out the other side with something I hadn't planned: my entire bookshelf as a single, queryable knowledge base.
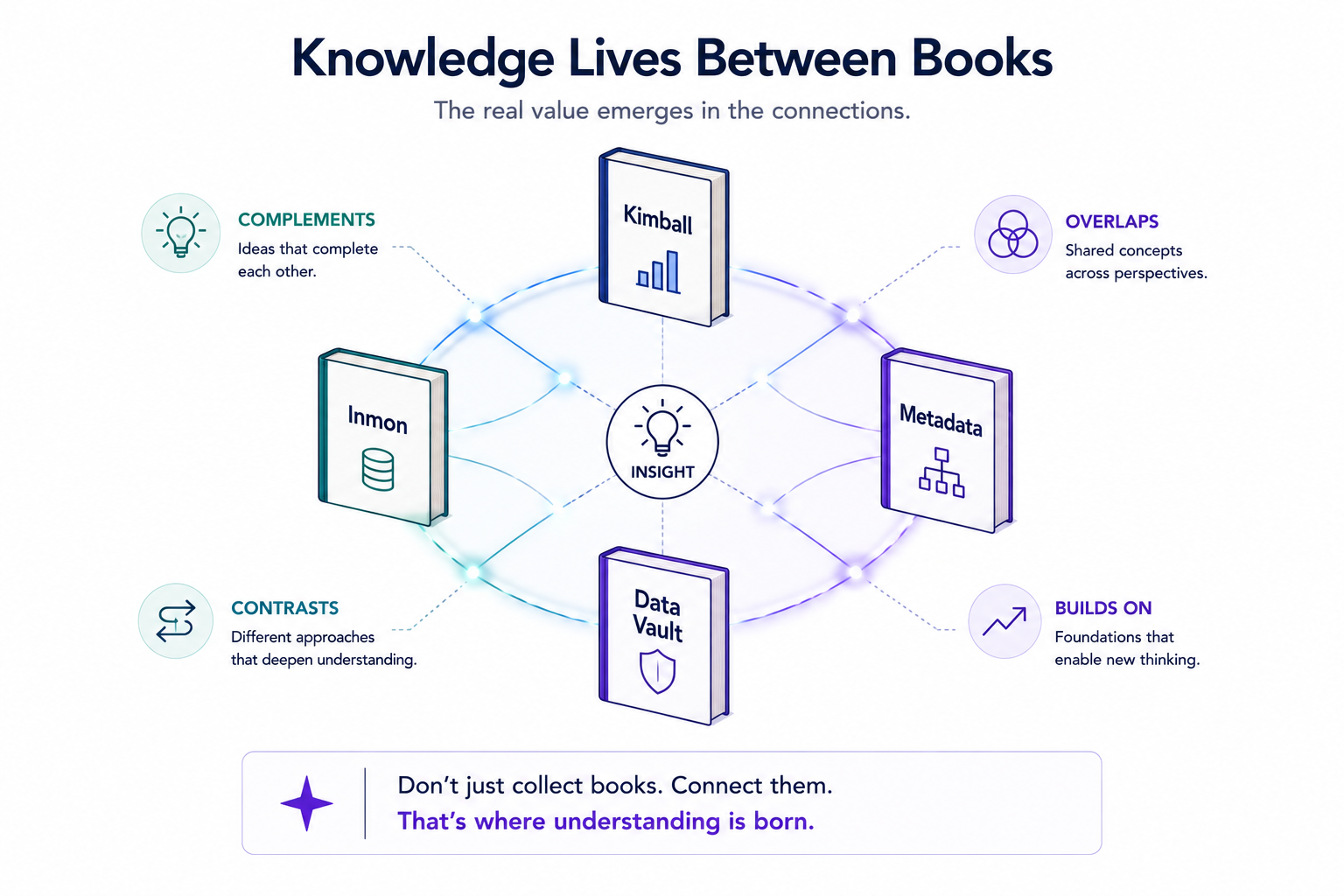
Archive versus source
This is the same trap I keep finding in my own systems, and in every organisation I've worked in. You treat the records you've accumulated as archive — things you keep, in case — when they're actually source — things you can read, at scale, to answer questions you haven't asked yet.
The difference is never the content. The difference is whether anything can read it.
A book sitting in a proprietary reader is archive. The same book as plain text in a folder, sitting next to 270 others, is source. Identical words. Completely different asset. One is a thing you own; the other is a thing you can use. The whole move — the only move, really — is getting from the first to the second.
And here's the part that surprised me: I didn't have to write anything. No summaries, no notes, no re-reading. The knowledge was already there, paid for, on my shelf. The work wasn't authoring. It was extraction. (If that phrasing sounds familiar, it's the same lesson I hit turning a decade of daily notes into a trip database — the records were already structured; I just hadn't pointed anything at them.)
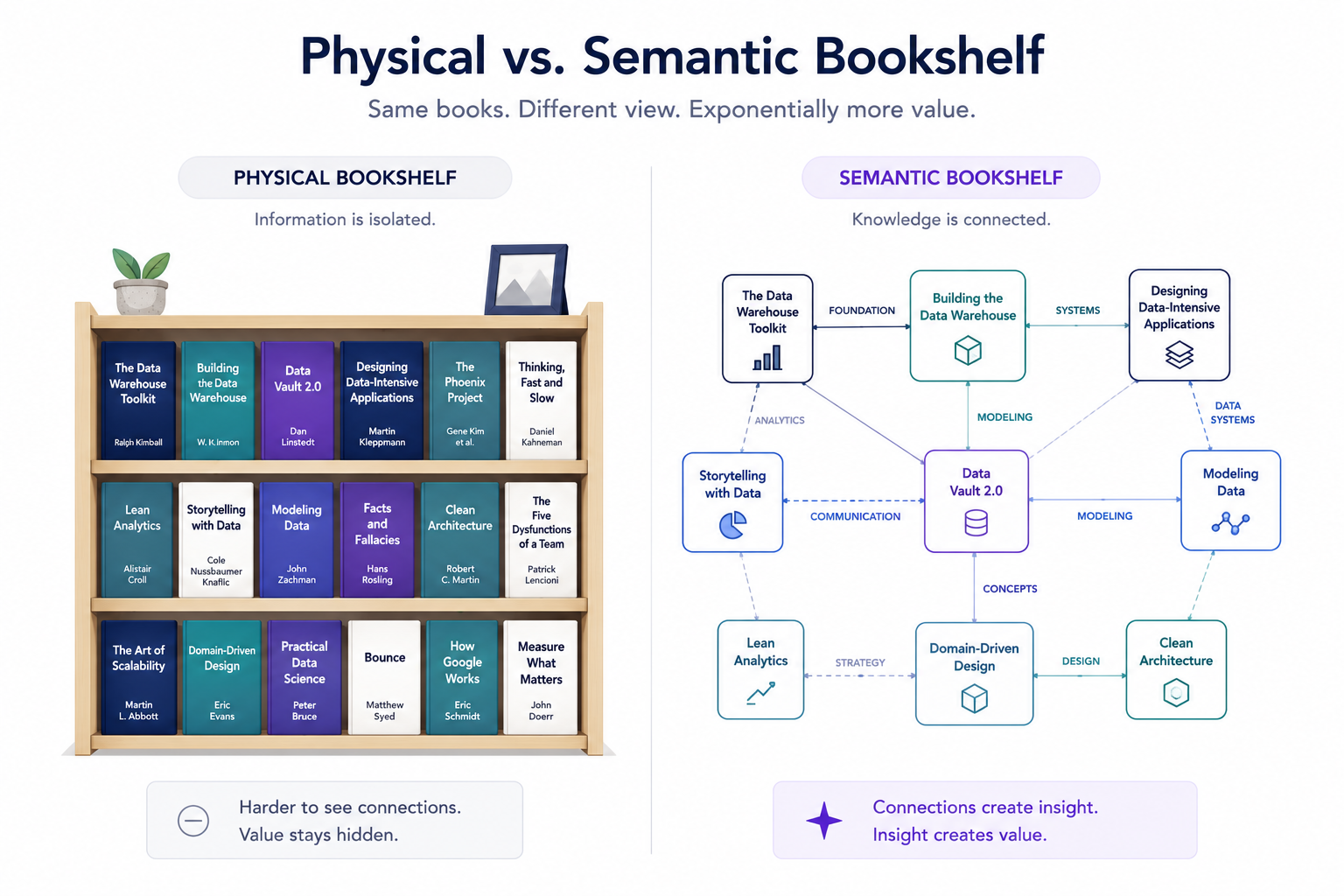
The honest, boring middle
I'll be deliberately vague about the mechanics, because the mechanics aren't the point and some of them are specific to a fight with one particular app. The ground rule was simple and worth stating: these are books I bought, freed for my own use, kept on my own disk — not shared, not redistributed. The interesting question was never "can I get the bytes." It was "what's the shape that makes them useful." So here's the shape.
Three steps. Each book goes: own the file → free the text → normalise to plain markdown. Out the other end: one .md file per book, named Author - Title, all in one folder. 84 megabytes. 13.8 million words. Two hundred and seventy-one books.
The honest part is the failures, and there were two kinds worth naming.
Format matters more than you'd think. I assumed I could extract text from the print-ready files — the ones that look like the page. Wrong. Those render the page as images: beautiful, and completely opaque to a machine. Twenty-one characters of real text in five pages. The reflowable format — the one that looks worse to a human — carries the actual text, cleanly. The lesson generalises hard: the version that looks best to you is often the version that's useless to a machine. Fidelity for the eye and fidelity for the query are different axes, and people reach for the wrong one constantly.
Some sources just won't come. Of my downloads, a chunk were in an older format whose protection I couldn't lift. Re-fetching them didn't help — the supplier only had the old version. So they failed, predictably, every time. I logged exactly which ones, set them aside, and moved on. A pipeline that pretends it captured everything is lying; a pipeline that tells you precisely what it dropped is trustworthy. I'd rather have 271 books and a known gap than a vague "most of them."
That's the whole middle. Own, free, normalise — and keep a receipt for what didn't make it.
What you get when the shelf can talk
Now the folder exists, and the folder is the product. Not any single book — the set, sitting where one thing can read all of it at once.
I pointed an AI assistant at it. The questions I'd never been able to ask my own library suddenly answered themselves:
- Across every data-modelling author I own, where do they actually disagree about the same concept?
- Summarise the three positions on temporal/bi-temporal modelling and tell me which one each author would defend.
- I'm about to talk to someone who wrote one of these — what's their core argument, in their words, and where do I push back?
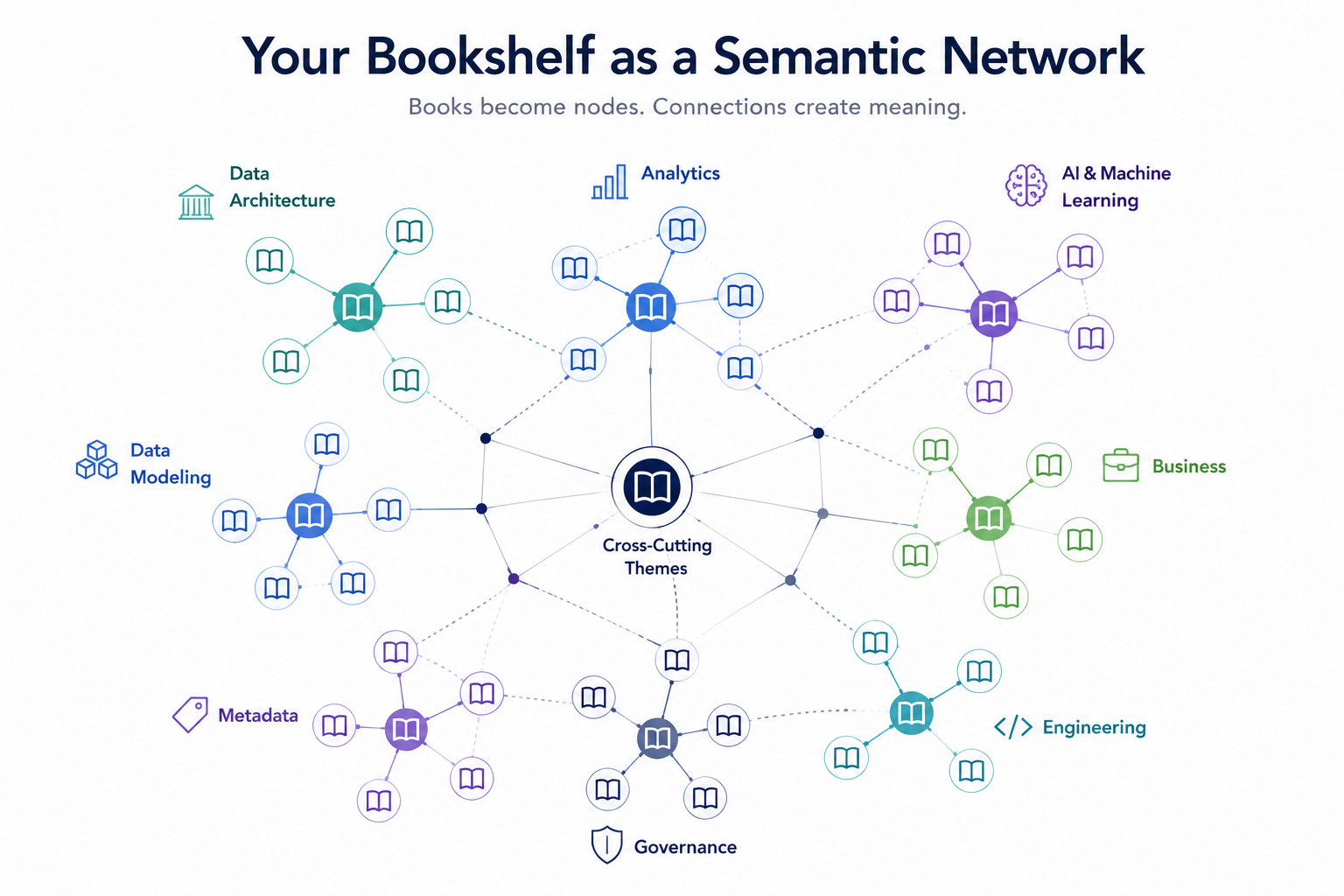
None of that is a feature of any reading app. It's a property of the corpus — of having freed the text and put it somewhere a model can range over the whole thing at once. The app gave me 271 sealed rooms. The folder gives me the hallway.
This is the formula I keep coming back to, and it's not magic: structure plus data plus AI gives you intelligence. The AI is the least interesting term. The data was always there. The thing that unlocked it was the unglamorous, almost clerical act of giving it structure a machine could enter — one consistent format, one folder, one place. The intelligence was waiting on the structure, not the model.
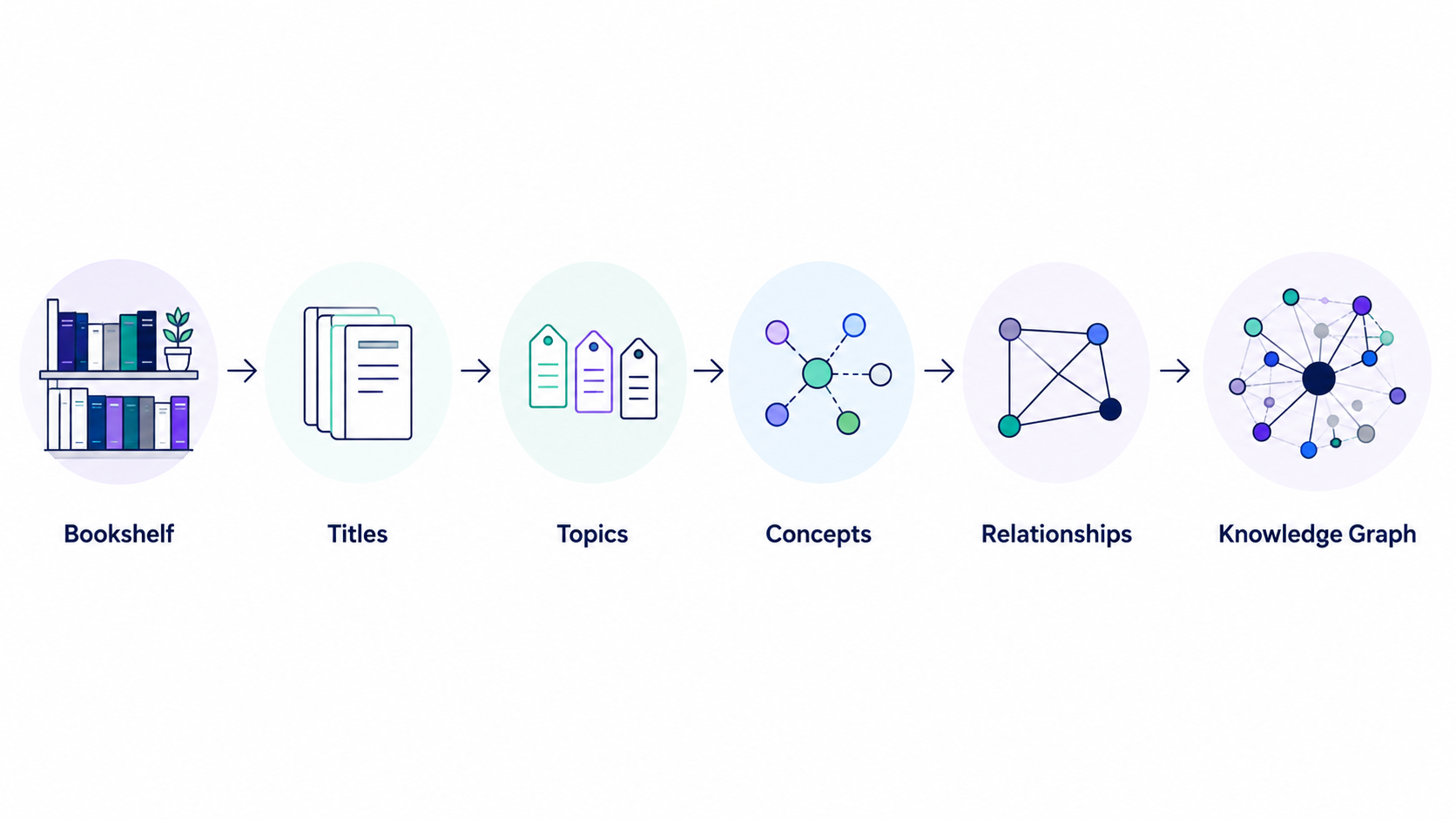
The part that isn't about books
I do this for organisations, and it's always the same shape. Walk into a bank's data function and the shelf is enormous: years of data dictionaries, model documentation, policy PDFs, regulatory submissions, the email threads where the real definition of a "customer" was actually decided. All of it owned. Almost none of it queryable. When the regulator asks "where did this number come from and who agreed the rule," the answer lives in 271 sealed rooms and nobody can stand in the hallway.
Everyone in that building wants to talk about the AI. Almost nobody has done the boring work first — turning the archive into a source: one shape, one place a machine can enter, and an honest account of what's missing. Skip that, and the AI just hallucinates confidently over a library it can't actually read. Do it, and the same questions I asked my bookshelf become the questions a risk team has been unable to answer for years.
My bookshelf is the smallest possible version of that project — a weekend, one person, a deadline. But it taught me, again, the thing I already believed: the magic isn't the model. The magic is structure. The books were always there. I just finally gave them a shape I could ask a question of.
That's the whole job, scaled up or down. Most organisations are sitting on a far richer shelf than mine and reaching straight for the AI. The order is backwards. Give the archive a shape a machine can enter, be honest about what's missing — then point the model at it. The intelligence was already in the building.
This is a sibling to Your Trips Are Already Structured Data — same lesson, different pile of records. If your own systems are full of "archive" you've never been able to query, that's not a tooling problem. It's a structure problem — and it's the one I help organisations fix.